

Мы уже много раз говорили про настройку ALE. Вроде бы, что там еще можно настраивать? Но все то, что мы с вами изучали ранее, это игра в песочек, для начинающих. Настоящие САПеры берут лопаты, миноискатели и идут в бой, повышать эффективность систем, сокращать ошибки. Сегодня в номере эффективная настройка SAP ALE. Эффективность заключается в тонких приемах, о которых большинство не знает, а они помогают существенно сократить количество ошибок при передаче данных.
Знаете две проблемы с транзакцией PFAL? Первая заключается в том, что PFAL не умеет отправлять уже уволенных физлиц, так как работает на логической базе PCH (есть нота с решением). Вторая, что при попытке отправить всю оргструктуру по пути анализа O-S-P бараны перемешаются с апельсинами и в принимающей системе будет каша. Для этого делают всякие изощрения вроде того, что нужно сначала переслать только объекты организационного менеджмента, затем соединения между ними, а потом уже табельные номера слать. Тогда система получатель корректно примет данные и создаст последовательно. При этом фоновые задания для отправки данных планируются в такой же последовательности, когда нам нужно ежедневно передавать изменения между системами. Сегодня мы научимся эффективно решать эти вопросы с помощью простых настроек SAP ALE.
Вы знаете, что структура IDOC с кодом HRMD_A включает в себя все интернациональные инфотипы для оргменеджмента, администрирования персоналом и рекрутинга. Там нет российских инфотипов, нет пользовательских. Это все можно включить в IDOC с помощью расширений, о которых я писал чуть ранее. Зачастую там много лишнего, что нам не нужно. Плюс у нас есть задача как-то научить систему различать штатку и кадры. Для этого вендор придумал механизм сокращения IDOC-ов. Идея банальна — все что нам не нужно в IDOC, мы можем выкинуть. Система создает своего рода сокращенное представление IDOC, наполняет только его и передает, соответственно, тоже только это сокращенное представление.
Как сократить HRMD_A
Мы разделим наш один IDOC на два. ZORG и ZPA соответственно для организационной структуры и данных администрирования персонала. В транзакции BD53 создаем поочередно два сокращенных IDOC с базовым типом HRMD_A. При создании мы указываем с помощью кнопочки Select, какие сегменты нам нужны. Рекомендуется включить системные сегменты и все те инфотипы, которые мы реально собираемся передавать. Давайте посмотрим на мой пример.
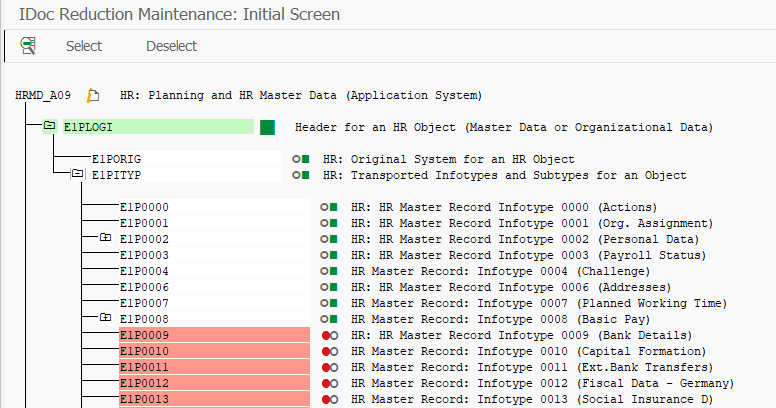
Сокращение HRMD_A IDOC ZPA
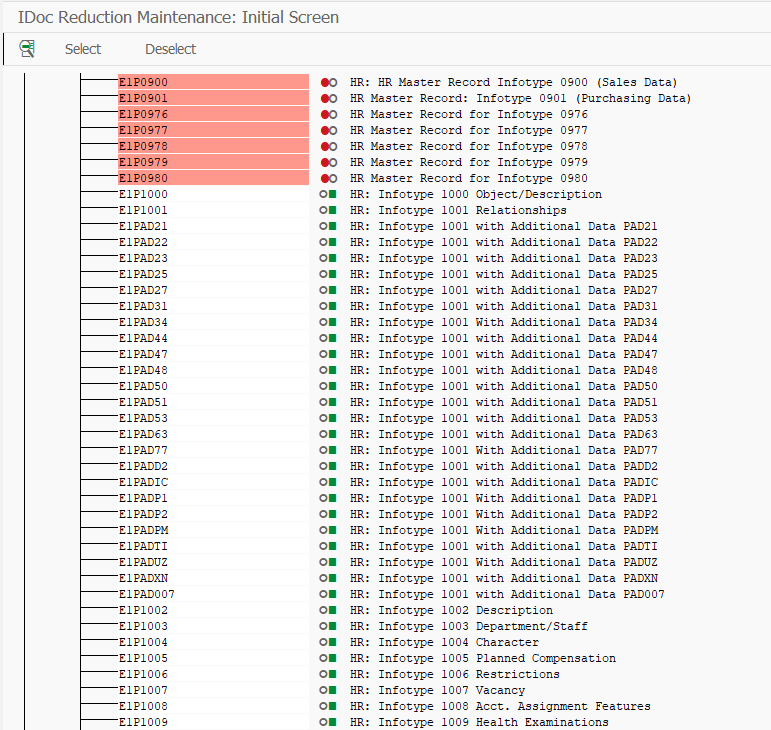
Сокращение IDOC ZORG
Дальше мы прописываем вместо HRMD_A новые два IDOC (транзакция BD64)
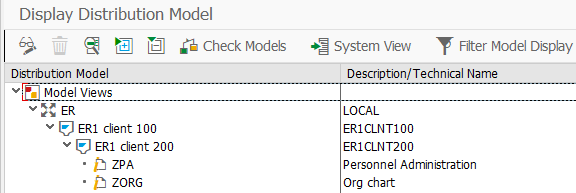
Модель распределения для сокращенных IDOC
Через меню перегенерируем парнтеров, чтобы прописать новый IDOC в исходящих/входящих параметрах. Не забудьте, что в целевую систему нужно перенести настройки по сокращенным IDOC. Для этого в транзакции BD63 можно создать транспортные запросы с настройками, а потом их перенести.
Не забываем подписываться, лайкать, репостить и всячески поддерживать отечественного производителя контента!
Теперь у нас в транзакции PFAL появятся два новых IDOC для отправки. Можно смело делать вариант для ZORG и для ZPA. Данные не будут пересекаться.
Оптимизируем работу с указателями изменений для эффективной интеграции
Далее у нас повляется интересная задачка. Мы разово передали структуру, табельные номера. Все хорошо. Пользователи начали колбасить данные, создаются указатели изменений, обрабатываются, все улетает. А в целевой системе получается каша. Как так? Когда мы создаем указатели изменений, а затем формируем IDOC из них, то система не учитывает что за чем должно идти. Все данные формируются в большие пакеты и отправляются по конвейру. Для того, чтобы нам гарантировать последовательность обработки данных в нужном нам порядке, существует механизм сериализации документов.
Посмотрим, с чем его волки едят.
В транзакции BD44 создаем группу сериализации. Это набор и последовательность IDOC, которые должны обрабатываться в одной последовательности. В нашем случае, это ZORG обрабатывается первый, а ZPA второй.
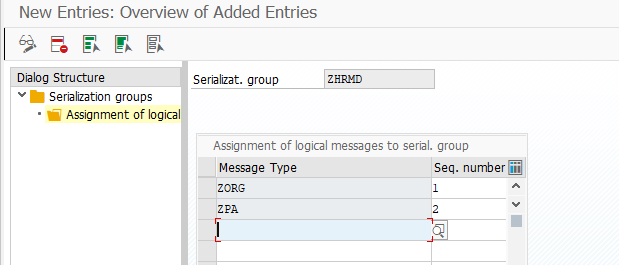
Создание группы сериализации IDOC
Половина настройки ALE готова 😉
Добавляем в модель распределения и партнеров специальный IDOC SERDAT с фильтром по нашей группе сериализации.
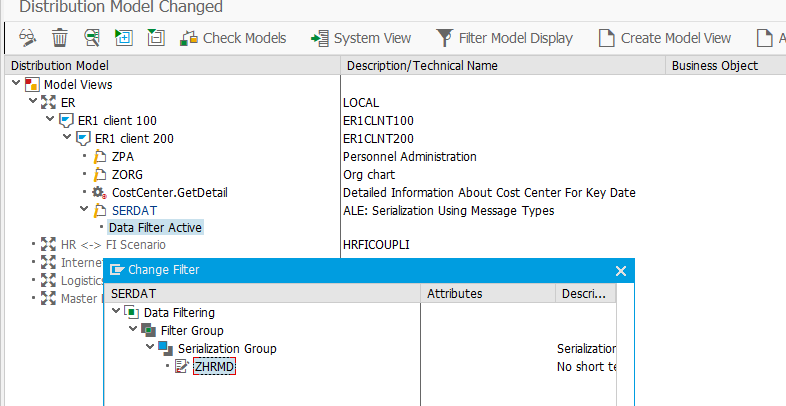
Модель распредления SAP ALE
В принимающей системе устанавливаем параметры обработки входящей группы сериализации в ракурсе TBD41.
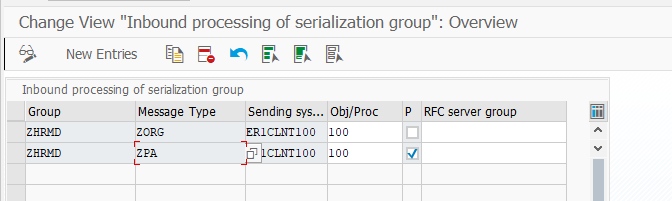
Настройка обработки входящей группы сериализации для настройки SAP ALE
Попробуем проверить. В ракурсе V_TBDA2 указываем активацию указателей изменений для наших двух IDOC. Изменяем данные в OM и в PA. В табличке BDCP2 мы можем увидеть, что система создала указатели изменений для наших изменений.
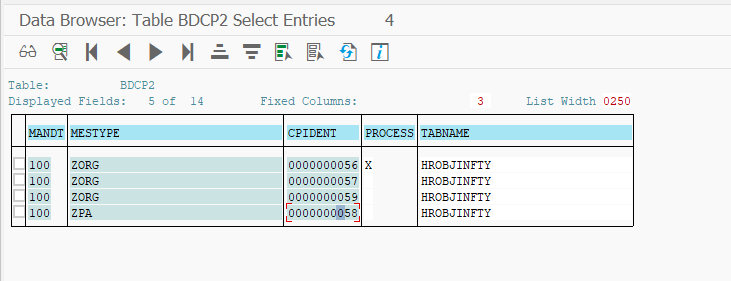
Просмотр указателей изменений SAP ALE
Для создания IDOC с учетом сериализации нужно запустить программу RBDSER01 с указанием нашей группы. Система создала два IDOC: один с данными ZORG, второй с данными ZPA. При это указатели изменений помечены как обработанные.
Далее мы запускаем программу RBDSER02, которая отправит в систему получатель срочную депешу SERDAT со словами, что вот вам два IDOC, не вздумай без меня их открывать.
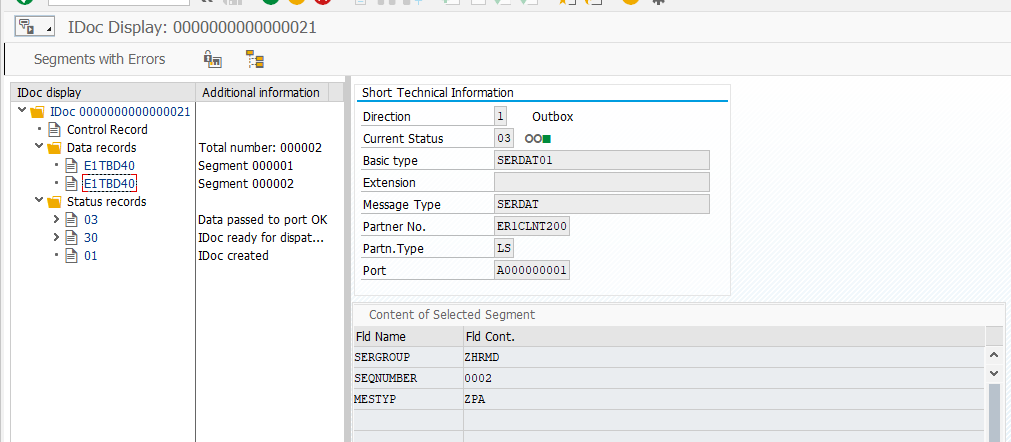
Отправка SERDAT IDOC
В то время, во входящей системе у нас в очереди будут висеть два наших IDOC. Нам осталось обработать их в правильной последовательности с помощью программы RBDSER04.
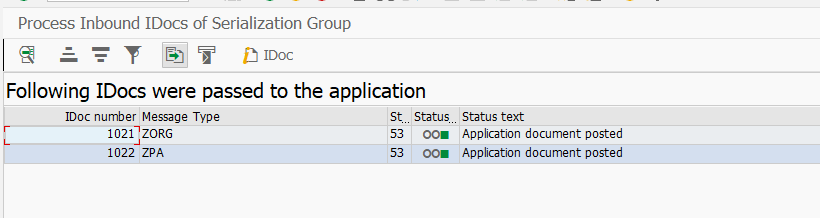
Входящая обработка группы сериализации IDOC
Как видите, все красиво ии по-полочкам обработалось. Никто никого не блокирует, все по уму.
В следующий раз я расскажу про настройку производительности IDOC, чтобы было вжух!
Не забываем подписываться, лайкать, репостить и всячески поддерживать отечественного производителя контента!