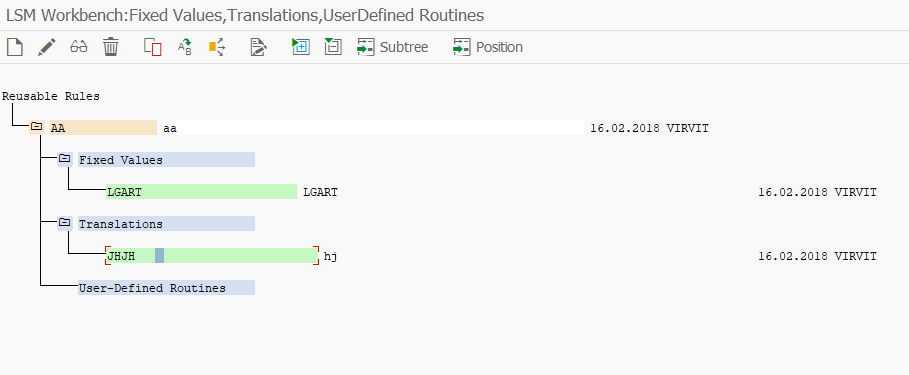
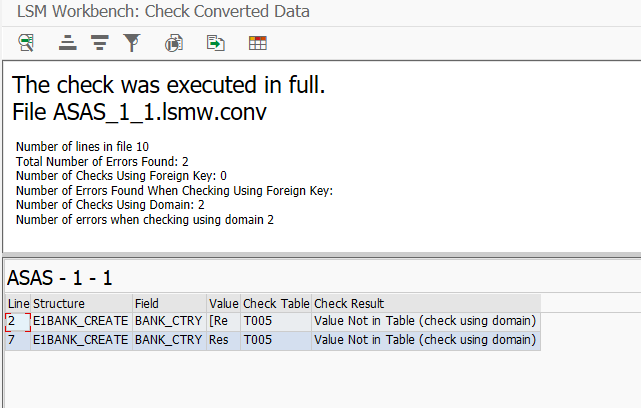
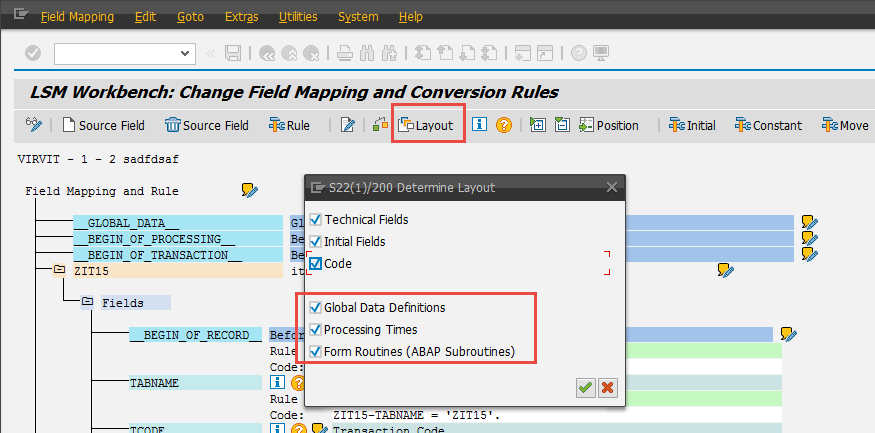
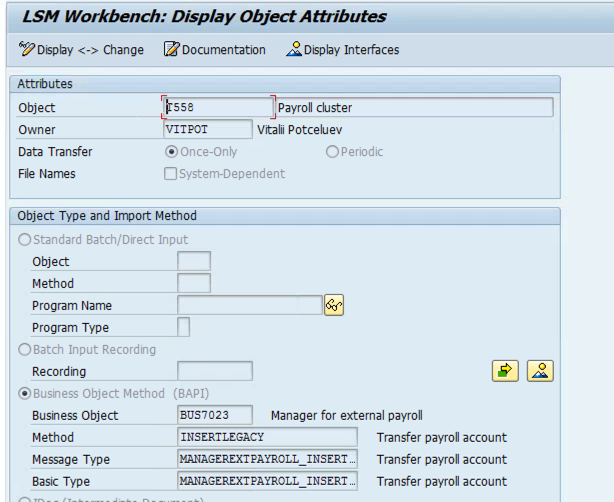
Правила преобразования в LSMW
С базовыми вещами в рамках миграции данных мы все умеем работать хорошо. Мы знаем как записывать проекты LSMW, мы умеем использовать разные способы загрузки (BAPI, BUS, IDOC, Batch Input) — мы с вами большие молодцы. Сегодня мы чуть внимательнее посмотрим на возможности LSMW для управления данными во время миграции. Правила преобразования в LSMW нужны как раз для изменения данных из загружаемых файлов в целевые поля системы SAP.